Overview of Data Abstract Architecture
In the What Is Data Abstract?, in the "Looking a little deeper" section, we explored a little about the layout of a Data Abstract environment and that Data Abstract is built on top of Remoting SDK. In this document we will look a little deeper under the covers.
Before we look at Data Abstract, we shall first take a look at what Remoting SDK is and how it acts as a foundation for Data Abstract.
What is Remoting SDK?
Remoting SDK is our powerful framework for building highly scalable distributed applications.
It has been developed from the ground up for each platform that it is available on (.NET, Cocoa, Java, Delphi, JavaScript) so that each is a 100% native solution. The great thing is that each platform is able to interoperate seamlessly, regardless of the device & operating system being used.
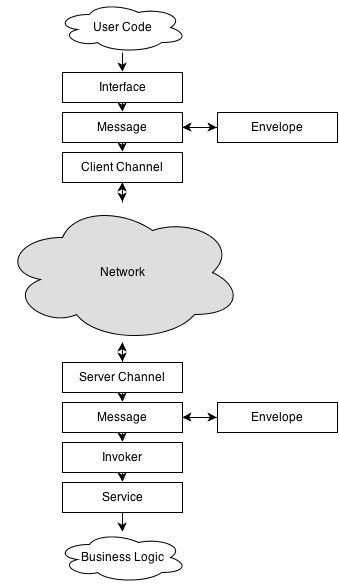
The diagram above gives you an overview of how the communication stack is handled. The heart of Remoting SDK is based on the concepts of Channels, Messages, Envelopes and Services, though there are two more under the hood; namely Interfaces and Invokers.
This might seem very complicated, but in reality nothing could be further from the truth. From a developer standpoint communicating with a service running on a completely different platform is as simple as:
var methodCallResult = sampleService.DoSomething()
The magic all happens behind the scenes. When the client code calls the DoSomething() method on sampleService, which is an instance of the auto-generated proxy class, the following happens:
-
The Interface class serializes the request to the server using the configured Message. The Message is then wrapped in an Envelope, if any have been set up (f.e. data is encrypted somehow). The resulting data package is sent over the wire by the Client Channel.
-
The Server Channel then retrieves the data package and pushes it to the Message component were it is unwrapped if needed. The resulting data package is provided to the Invoker, which reads the requested service, method names and method parameters from it. Were-upon the Service method is invoked, and the actual job performaned.
After the Service method has finished, its result (or any exceptions occurred) are serialized, wrapped, and sent back over the wire using the Server Channel (using a similar pipeline to the client side described in step 1).
- The Client Channel then retrieves the data package, unwraps it and provides the serialized data package to the Interface's method that initiated the remote service call. This method then deserializes the provided data package and provides the method result back to the user code.
The magic happens out of sight so that you can focus on the more important aspects for your app.
To read more about the SDK, checkout the pages concepts section of the local Remoting SDK documentation, otherwise look at the old documentation Wiki. Remoting SDK samples can be found in the same location as the Data Abstract samples if you wish to explore using Remoting SDK.
Delving deeper into Data Abstract
Data Abstract takes all of the benefits of the seamless communications that the Remoting SDK framework provides and builds on top of it a layer that is highly focused on providing database agnostic data access.
The major benefit of this, is that you can interact with a remote server without worrying about what platform that server is running on, or what communication protocol to use. Instead you can focus on working with the data. Using Data Abstract you can easily retrieve one or more tables from a remote server using a single line of code:
this._dataModule.DataAdapter.GetTable<DASamples.PCTrade.Customers>()
NSDictionary *tables =
[remoteDataAdapter getDataTables:@[@"Customers", @"CustomerOrders"]];
Lets take a closer look at what is happening here, starting from the client side of things.
Client-Tier
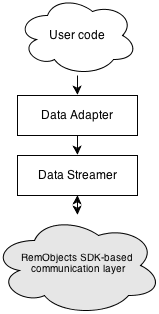
The RemoteDataAdapter also contains an instance of a data streamer which encodes & decodes the data sent to and received from the server, and internally handles writing and reading to the data tables.
With this, the RDA is capable of requesting data tables from the server - be it by fetching the tables by name, subsets of these tables using Dynamic Where and Dynamic Select, or running more complex queries using DA SQL which causes the server to construct a data table dynamically.
Once received, the data is made available in a data table class1 for the client to consume. The client code can then access the data in these tables, and make modifications, which the data table stores internally as Delta Changes which are essentially a list of differences between the original data and the changed values.
At a time of the clients choosing (some applications might do this automatically in the background; others work offline and provide an explicit UI option), the client can choose to apply the changes back to the server. To do this, the RDA looks at the delta changes accumulated in the data tables, and build Deltas with them. The deltas will then be encoded using the data streamer, and sent to the middle-tier server to be applied to the backend database.
Once the changes have been applied successfully, the RDA will then merge the delta changes back into the original data, to reflect that the local data table has no more pending changes.
Individual delta changes might also fail to be applied on the server (for example if other clients have updated data and applying the changes would result in data inconsistencies). If that is the case, the rejected delta changes will be sent back to the RDA, with error information, and the RDA will either raise exceptions or display a Reconcile Dialog allowing the user to fix the problem.
Middle-Tier or Server side
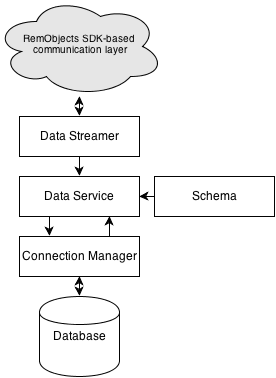
On the middle-tier the DataStreamer is the first port of call. As noted above the data streamer encodes & decodes the data requests, updates and results for transmission to and from the client. There are several different data streamers available such as JSON or XML, but the most commonly used is the Bin2DataStreamer, which provides a highly optimized wire format that is ideal for sharing data between Data Abstract clients and servers, with little overhead both in size and processing time.
Once the data has been decoded by the DataStreamer it is passed to the appropriate Data Service (remeber that the client's RemoteSerice specifies the name to the data service). There can be one or more Data Services available which provide access to the database tables and handles the interaction between the Connection Manager, the Schema and the DataStreamer for the application.
These services are application specific classes which descend from a predefined TDataAbstractService base class that provides all the core functionality for data access. If you create your own custom server then you can then extend those classes with custom code to fine-tune the data access, although a large percentage of Data Abstract servers work without any user-written code; indeed we recommend using Relativity server as it should cover most of your needs.
Every data service holds a reference to a Schema, which defines the mapping of the underlying backend database (or databases) to the structure of data exposed by the service. Schemas are usually edited in the Schema Modeler or Server Explorer and included with the server application as components (TDASchema, in Delphi) or resource files (.daSchema files, in .NET), but can also be loaded at run-time or maintained and managed with code, for maximum flexibility.
The data service also references a ConnectionManager which coordinates and maintains the different database connections available to the application and handles connection pooling and recycling. One global connection manager is commonly used application-wide, which is different than the schema as that is usually tied to an individual data service. The data service will acquire a connection from the manager when it needs to access the database, and releases it back to the global pool when done.
The data is sent between client and server in so called Data Tables. A Data Table is essentially a record set, a list of rows that contain the requested data. Data tables retrieved from the client can be exact matches of tables defined in the schema, subsets of them (when using Dynamic Where and Dynamic Select) or more arbitrary sets of data combined from various tables, when using more sophisticated data access models such as DA LINQ or DA SQL. Regardless of the form of the data requested by the client, the Query Execution Engine inside the data service will handle the incoming request and use the schema and a connection obtained from the connection manager to gather and assemble the requested information into one or several data tables.
Data can also be sent in the form of Delta changes that are received from the client when changes to the data have been made. A delta is a collection of individual Delta Changes, each of which represents the modifications the client may have made to an individual record. Deltas are sent across the network using the same encoding as data tables, so the data streamer is used to decode the incoming data packet and obtain the delta contents. The data service will then process each delta change, and once again use the schema and Business Processors to convert each individual delta change into an update to the actual back-end database.
Business Processors, which can be either created automatically within the data service or manually dropped as components and configured via properties and event handlers for more fine-grained control, help with the data access and coordinate what queries need to run against the back-end database to retrieve the necessary data.
If any Business Rules are specified they will be processed based on the appropriate event (for instance on the deletion of a table row, or updating data in a field) which may affect the data returned to the client.
Once the data has been gathered, the data service will then use the data streamer to encode the data tables into a form that will then be sent across the network, and back to the client.
Notes
-
Whether as DataTable instances inside a Dataset on .NET, TDADataTable on Delphi, DADataTable on Cocoa or DataTable in Java) ↩