DA SQL
"DA SQL" is safe client-side SQL querying.
For decades now, SQL (short for Structured Query Language) has established itself as the standard language for expressing database requests. Originally devised to be easily understood and written even by non-technical persons, SQL makes it easy to describe simple and mid-level data queries, but at the same time provides the flexibility and power for experienced SQL developers to write complex and very expressive queries.
In its simplest form, an SQL expression is used to query for all data from a given table, or specify a subset of fields or records to retrieve. For example, the query:
SELECT CustomerID, Name FROM Customers WHERE Name = 'Miller'
would request the two specified fields, for all Customers named Miller. However, more complex SQL queries can work across multiple tables, aggregate and join data, and otherwise express pretty complex data access scenarios.
SQL and Multi-Tier
Traditionally, SQL has been constrained to be used in two-tier client/server applications, or on the server (a.k.a. "middle") tier of multi-tier apps.
In the classic client/server scenario, client applications would contain or generate SQL statements that were run directly against the database, without any means for business logic or fine data access restrictions to be applied in between. Because clients had full access to the SQL of the back-end server, they could query any data they pleased, and make extensive changes without control. Great flexibility on the client-side was achieved by sacrificing control.
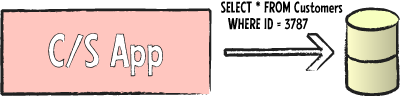
When Multi-tier architecture came to replace client/server applications, direct SQL access to the back-end server was banished to the middle tier. Only the business server could communicate directly with the back-end database through SQL, while clients were usually restricted to retrieving full record sets, or sets of data filtered by criteria specifically exposed through the business server (maybe the server would expose specific method where clients could ask for data filtered by a given field). This consolidated control over data access and updates to the middle tier – where it belongs – but sacrificed flexibility on the client in how data could be queried and obtained.
(Some so-called multi-tier solutions try to circumvent this problem by simply passing SQL through from the client to the database; that is a Very Bad Idea™, as it completely bypasses all business logic in the middle tier, and essentially turns the middle-tier server into a glorified proxy. The result is really a Client/Server application, once again.)

Enter DA SQL
DA SQL, a technology introduced by and unique to Data Abstract, changes all that, by providing clients the full flexibility of SQL queries to describe their data needs without giving up the control held in the middle tier. While traditional client/server applications would allow clients to write SQL that ran directly against the back-end database, as discussed above, DA SQL statements sent from the client application are processed and run against the data as published by the business tier, allowing that tier to keep full control over data access and updates.
DA SQL statements will use field and table names as they are defined in the middle-tier schemas of the Data Abstract server, and will automatically be restricted to the data and fields that the middle tier allows access to.
For example, an extensive Customers table might be exposed to a client application for sales personnel with two restrictions: (a) only a subset of, say, 10 fields is available and (b) every sales person may only access customers from his or her region. This is data access business logic that would be encoded in the schema or in custom code written for the server application, making sure that whenever a client application retrieves or updates data, these restrictions are upheld.
DA SQL allows client applications to use SQL to perform data queries, without giving up or bypassing this (or any other) business logic in the process. For example, the client application might send the following query to the middle-tier server:
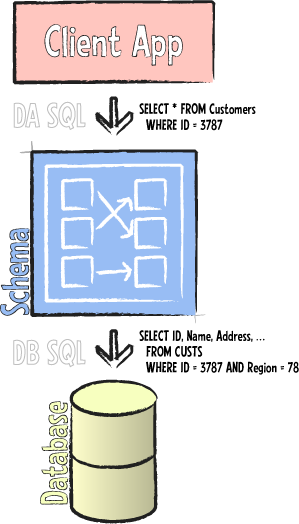
SELECT * FROM Customers WHERE Name = 'Miller'
Whether the application allowed the end-user to type this query or generated this SQL code as part of a query builder or some other form of UI, the intention is the same: the application is asking for all fields of the Customer table where the customer in question is named Miller. But as we recall, data access constraints were set on the server, so the client will not actually receive all fields of the customer table (nor all customers, world-wide, that are named Miller): because DA SQL is processed and executed in the middle tier, business logic will be applied to constrain the access and enforce the business rules we set forth above. As a result, the actual database query that will run against the server might look something like this:
SELECT ID, Name, Address, ... FROM Customers WHERE Name = ?Miller AND Region = 78
DA SQL, which has deep understanding of the back-end database /and/ subset that the schema exposes to clients, was able to craft a new query – combining the details from the request it received from the client with its own filters, in both SELECT and WHERE clause.
DA SQL Flexibility
While the above is a simple example (and, to boot, a data request that could have easily been expressed, client side, without the need for SQL), DA SQL allows much more complicated and detailed requests to be formulated, which would still benefit from full protection of business logic.
For example, a query could JOIN together different tables, employ nested queries or have a much more elaborate and complicated WHERE clause. Still, DA SQL would enforce that data can be accessed as permitted by the schema and other server-side logic.
At the moment, DA SQL supports a subset of the SQL92 standard, with most querying options commonly used, including JOINs, nested queries and of course extensive SELECT and WHERE clauses to describe subsets of fields or records to retrieve. Over time, it will be expanded to support all features of SQL92 that are applicable.
More details on the current set of supported SQL features can be found here.
How Does it Work?
It is important to understand that DA SQL query statements are never directly passed through to the back-end database. This completely eliminates the risk of SQL injection attacks or malicious clients executing unwanted actions as part of what looks like an innocent SELECT request.
What DA SQL does, basically, is to process incoming SQL queries and return result data back to the client. So the main task of the DA SQL is to execute SQL statements against the objects in our schema. The diagram below illustrates the process:
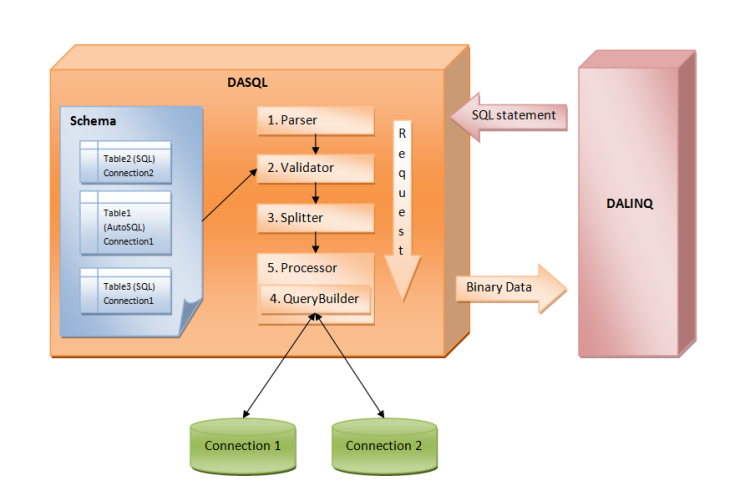
DA SQL takes an incoming SQL statement and processes it. In essence, the DA middle tier is behaving like any SQL based backend server, in that it is fed a SQL string specifying the data to query, and will fetch a result set in return.
The crucial difference is, that instead of directly working against a data store, DA SQL is applied against your schema. This way, all your data mapping and business logic is preserved, while giving you the full flexibility of SQL to express your query (opposed to just specifying a table name and a more constrained TDAWhere XML).
Processing is done in several stages; each stage is controlled by certain objects.
First DA SQL receives a request with a SQL statement and passes it to the SQL Parser. The parser makes sure that the SQL statement is valid in syntax and converts it into an internal representation that describes the SELECT, INSERT, UPDATE or DELETE statement it represents, so that is more easily handled by the following steps rather than a chunk of text. The result is an object that holds all information required to fetch the requested data.
Second comes validation against the schema. While the first step made sure the SQL was a syntactically correct, this second pass validates the request against the tables and fields that are defined in the schema. Remember that identifiers in a DA SQL query are objects in your schema, not the back-end database. The validator makes sure that the query only accesses elements that are properly defined and exposed in the schema. If a statement touches a table (or fields of a table) that is not exposed in the schema, then it will be rejected with an "Unknown Table" error, even though the actual table might exist in the backend database.
Third, once the query is determined to be valid, the next task is to analyze the query and generate a Query Plan for fetching the data in the syntax of the respective back-end databases (“DB SQL”) to fetch the data as needed. Here, it will apply any and all business constraints to make sure it accesses only data that is permitted (for example, as seen above, a query with * asking for all fields would be translated to only retrieve the fields actually published via the schema). It will also apply any column mappings or database abstraction defined in the schema.
In the ideal case, the result would be a single SQL statement to be run on your backend that fetches all data in one go, but, depending on your table configurations, that might not always be possible.
DA SQL abstracts this away from you by splitting the query into separate tasks, the so-called "Black Boxes", where necessary. Each black box can be fetched independently.
Imagine the following scenario: You're passing a query like this
SELECT c.id, c.name, o.sum FROM customer c
INNER JOIN orders o ON c.id=o.custid WHERE o.date = :TODAY
to DA SQL, where the Customer table is based on an AutoSQL statement, but Orders is not (it might be using a hard-coded SQL statement, or even a stored procedure). Because the way Orders are fetched is hard-coded in the schema, we cannot build a single SELECT statement for getting both tables out of the back-end. Instead, DA SQL will split such a request into two Black Boxes, where the first one will be run with an ad-hoc SQL statement such as
SELECT c.custid, c.name FROM cust c
to fetch customers (note the different field names, now representing entities in the back end database), while the second Black Box will of course use the statement hard-coded inside the schema. Where possible, a Dynamic Where might be applied to the second box, to keep data fetching to the absolute minimum.
Another reason why a DA SQL query might need to be split into two or more boxes could be if the tables used in the query originate from different databases (i.e. using different connection strings), when using DA NET.
DA SQL will, of course, try to avoid splitting the query into more boxes than necessary; in the ideal case, when all tables use AutoSQL and come from the same database, data can always be fetched in one go.
Fourth, Each of these "black boxes" now independently fetches its data.
Fifth, in the final step, DA SQL will take the data it received from the different boxes and merge it into the final result set according to the JOIN or UNION conditions specified in the DA SQL query. The resulting record set will then be streamed into binary format and passed back to the client, just as a plain non-DA SQL request would have been.
All of this is happening transparently on the server – all the client sees is the resulting data matching its query.
DA SQL & DA LINQ
One prominent feature of DA that leverages DA SQL under the hood is DA LINQ. DA LINQ is a .NET technology that allows you to use LINQ constructions to operate with data. The LinqRemoteDataAdapter can generate ad hoc SQL queries based on the LINQ query, and will use DA SQL to process them.
It is important to realize that while DA LINQ depends on DA SQL, the reverse is not true. DA SQL stands as its own technology and can be used separately from DA LINQ, including client platforms that do not support LINQ, such as Delphi or Xcode.
Find Out More
DA SQL is mainly a server-side technology, and available in DA/.NET Servers and the cross-platform standalone Relativity Server. It can of course be consumed from clients written in all editions of the Data Abstract library.
For .NET client development, an interesting technology built on top of DA SQL is DA LINQ.