Why Multi-Tier?
Data Abstract is what is commonly referred to as a "multi-tier" framework, meaning that it is based on the principle that data access should be separated into multiple levels, or tiers – usually three. To understand why multi-tier database access is the preferred solution for most scenarios, we need to take a step back and look at the principles that were applied to data access before.
A Step Back into the 90's – Client/Server
Back in the 90's (and before), there were basically two types of database applications being written: so-called "Desktop" and "Client/Server" applications.
The term desktop database application most commonly referred to single user applications that talked directly to a local database – often something like dBase, Paradox or FoxPro – installed on the user's computer. This was in the days before all-pervasive networks, and these applications were usually standalone programs that did not interact with the outside world or share data with other systems or users.
On the higher-level side, there were Client/Server applications which shared many characteristics with their desktop counterparts in how the application was structured, but accessed a "big" database system, usually running on a dedicated server or server farm on the company's network that was shared by many users.
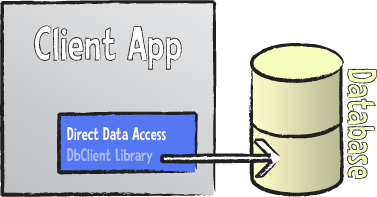
The common element of both Desktop and Client/Server applications (and, as we'll see, the major weakness of the Client/Server paradigm) was that most, if not all, business logic was hard-coded into the application itself, with the database basically taking over its traditional role of a data storage – nothing more.
Client/Server applications suffered from several drawbacks inherent to their architecture:
- Because all business logic was implemented on the Client application, the code enforcing this business logic was spread all across the network and duplicated on each workstation. Changes to business logic or business rules usually implied redeploying new client software to all users. A big administrative effort at best, and downtime for large parts of the workforce at worst.
- Another problem associated with having business rules enforced on the client tier was (and still is) that it makes the system vulnerable to attacks, as client systems can be compromised. With client software deployed on hundreds of computers throughout the company or even outside the controlled network, it cannot be guaranteed that malicious users do not try and succeed at "hacking" the client software or even write their own replacement software – directly accessing the database and bypassing all enforcement of business rules altogether.
- Somewhat related to the above point is the fact that, again due to the very nature of Client/Server architecture, the back-end database needs to be opened up to be accessible across the network by all clients. And while all modern database systems do provide sophisticated authentication mechanisms, opening a database to the network (or the world) is always a risky endeavor for two reasons. First, because commonly used database back-ends bring with them well-known attack surfaces that hackers can exploit to compromise the system. Second, because client systems themselves need to authenticate with the servers and in many cases that authentication info can easily be extracted from the client software.
- Lastly, the network interface provided by most back-end database systems has been designed for access over the local network, using fast connections and no firewalls. Nowadays, most client software needs to run outside the controlled network – be it from employee's home offices or from laptops on unsecure connections on the internet, in airport lounges or internet cafes. Even ignoring the risks of opening up a database server to these scenarios outlined above, in many cases such connections will be unreliable or inefficient.
Multi-Tier to the Rescue
How then does multi-tier architecture solve this problem? Simple: by partitioning data access into more tiers than the traditional Client/Server model (which is also sometimes referred to as two tier), with each tier performing the tasks for which it is best suited and can be trusted.
While in theory the multi-tier architecture (as indicated by the name) can consist of a variable number of tiers, the most commonly used scenario is a three-tier solution, which roughly maintains the concept of client and server as they were common in the two-tier era, but inserts a third tier (often called "middle tier" or "business tier") in between.
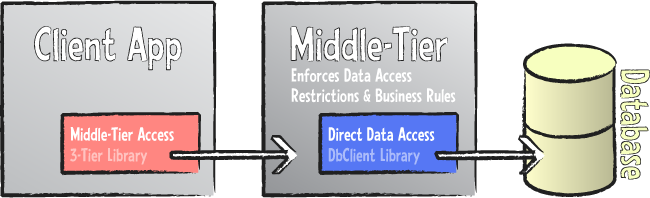
From a very high level point of view, one can say that the middle tier performs two main tasks:
- It isolates client applications from direct access to the back-end database.
- It consolidates the enforcement of business logic and business rules in one controlled place.
Isolating the client from access to the database means that the client applications no longer connect to or communicate directly with the database server, nor do they directly access the tables or raw data defined in the database or databases. All access to data – both for reading and for manipulation – goes through the middle-tier server, which maintains full control over the data access.
Implementing the business logic on the middle tier means that there is now one central place where these rules are enforced, and – because all data access has to go through the middle tier – there is no way for client applications to bypass those rules.
The middle-tier server will usually be deployed in a secure location, for example as part of the server farm also hosting the databases, and it exposes a very limited interface to the network that provides nothing more than what is actually needed by clients. And it will make use of a standardized internet protocol, such as HTTP or Web Services, to make sure this access works seamlessly across the global network, if needed.
Compared to the Client/Server model, the client application is trimmed down to a so-called "thin client" that provides everything needed to deliver a rich user interface to the end user – but anything related to ensuring data integrity is now handled on the middle-tier server. The very worst a "hacked" or otherwise compromised client application is able to do is to obtain access to the same data and perform the same kind of changes that are permitted anyway – anything else will be rejected by the middle tier.
Why Data Abstract Instead of Other Frameworks?
Data Abstract is certainly not the only multi-tier database framework available, so what is so special about Data Abstract that makes it the premiere solution for thousands of customers? Listing all the benefits and the conceptual advantages of Data Abstract would far exceed the topic of this White paper, so let's concentrate on two of the most fundamental advantages.
Reason #1: A Complete End-to-End Solution for All Aspects of the Multi-Tier Architecture
While many of today's database frameworks are written to support multi-tier scenarios, not many of them were designed from the get-go with multi tier in mind.
Take for example ADO.NET, the current database framework from Microsoft. While ADO.NET is certainly prepared for use in multi-tier solutions and provides certain features that make it well-suited for multi tier1, there is a huge gap between having basic "3-tier ready" features in the data layer and having a full framework that lives and breathes 3 tier. For example, ADO.NET is based on disconnected data sets, meaning that client applications work with sets of data that were retrieved from a back-end database, but are then worked on without live connection to the database, and changes to this data are first persisted locally to be applied back later. But that is only one aspect of a full multi-tier architecture, and only a very small part of the big picture. For example, ADO.NET makes absolutely no provisions for actually separating client and middle tier, nor does it provide solutions on how the two tiers should best communicate – it is up to the individual developer to reinvent the wheel and put the different pieces together.
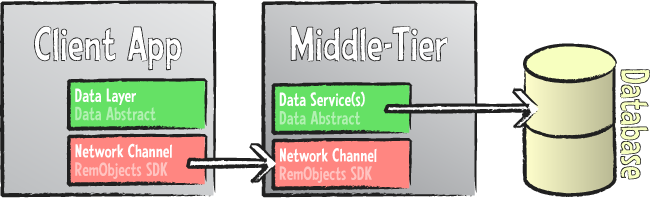
In contrast, Data Abstract provides a holistic framework that covers all parts of the multi-tier data access story – not merely the data access itself, but also:
- How client and server communicate (leveraging our Remoting SDK).
- How authentication of clients will be handled.
- How parameters or conditions for data retrieval will be passed between client and server.
- How business rules are applied to the data.
- How error conditions will be passed back from server to client if updates fail.
Data Abstract provides a consistent framework that solves all these questions – and more – for you, ready to be used.
It may come as a bit of a surprise, but many Data Abstract servers out there contain little to no user code. A new server application is created with the click of a few buttons as part of our development IDE wizards and will perform all functionality needed from a full-fledged, deployment-ready middle-tier server from the word go. (And most our users today use our Relativity Server, which saves you even that little bit of work.)
That is not to say that Data Abstract locks the developer into doing things any particular way; quite the contrary. One of the basic design principles of Data Abstract was to provide a very open architecture that allows developers to implement multi tier the way that best suits their needs. Data Abstract provides a clear path of recommended "default solutions" for all aspects of the multi-tier architecture, but developers can customize or entirely replace any part of it to meet their own needs.
It is up to the project architect or individual developer to decide whether they want to follow Data Abstract's architecture in its entirety (which is completely appropriate for the vast majority of real life projects) or want to apply their own concepts to parts of the process to better suit specific needs set forth by the project's demands.
Reason #2: The Database-Agnostic Way to Implement Middle Tiers
Virtually all multi-tier frameworks available rely on a tight coupling of middle-tier code to the actual database back-end. Developers are required to write a lot of code that is specific to the database at hand, or many components need to be dropped, configured and directly associated with back-end database tables. Oftentimes, this code or these components will contain hard-coded SQL strings for retrieving or updating data, which might or might not be auto-generated. In any case, what seems like a perfectly reasonable approach for accessing two or three tables in a simple application soon becomes unwieldy and, more importantly, next to impossible to maintain when dealing with tens or hundreds of different tables – all of which might change and evolve over the lifecycle of the application.
Data Abstract takes a radically different approach by introducing the concept of Schemas that define the structure and layout of the data accessed by the middle tier and published to the client.
A schema is an XML-based file that defines the data tables used by the application in a structured and well-defined manner. The schema abstracts the actual back-end database and all the details associated with it – how to access it to retrieve and update data, what SQL syntax to use, etc. – from the actual code in the middle (and client) tier. Basically, the schema defines the view of the data that your project will work with, keeping it separated from all the grunt work that is needed for the actual data access.
As a result, developers can concentrate on writing the client and business logic of their application, because all the data access to back it up is provided seamlessly by the Data Abstract library – based on information defined in the schema.
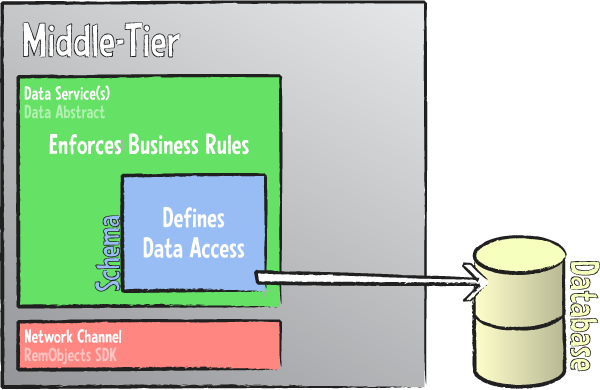
Data Abstract provides a powerful application – the Schema Modeler (Server Explorer on the Mac) – to let developers or project architects define the schema for their project visually and in a RAD (Rapid Application Development) way. Schema Modeler integrates deeply with the supported development environments and at the same time provides a user interface that is comfortable to use for non-developers, allowing the team to separate the work, for example letting a database administrator define the schemas that the developers will then code against.
Because all data access is defined in the schema and automatically provided by the Data Abstract library at runtime, a skeleton middle-tier server requires literally no custom code, so developers can concentrate on implementing business rules – as well as the client application – instead of investing time in writing data access plumbing that Data Abstract can take care of on its own.
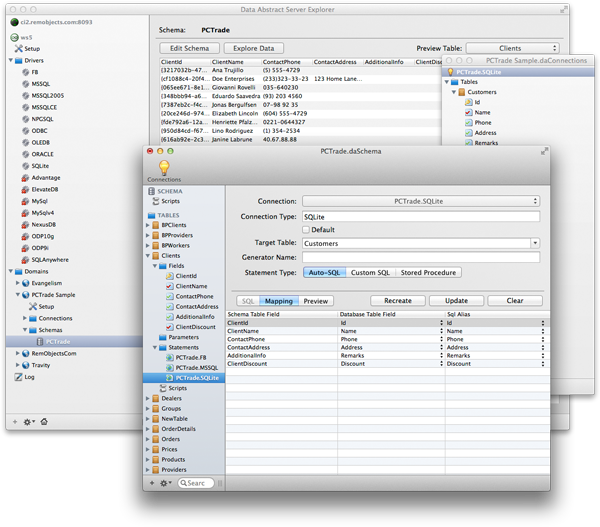
Schema Modeler is available as native app for both Windows and (shown above) Mac, re-designed from the ground up for each platform.
One of the nice side-effects of Data Abstract's approach of using schemas is that the business logic code is automatically database agnostic and not tied to a specific database system or structure. Applications can be adapted to target different back-end databases without any code changes and minimal or no changes to the schemas involved.
Data Abstract's schemas are a powerful and flexible concept, and the above introduction can only scratch the surface of the many benefits they bring to your multi-tier architecture. You can read more about Schemas here and explore other topics on Data Abstract Technologies and Concepts to learn more.
Footnotes
-
As a matter of fact, Data Abstract for .NET is partially based on ADO.NET and leverages those parts of it that were designed for multi-tier use. But it expands on what is provided by ADO.NET to offer a full multi-tier experience – as outlined in the following. ↩