Column Mappings
Data Abstract introduced the concept of Column Mapping as one of the core features enabling cross database support within a single schema.
This cross database support means that a single schema can define the structure of the application's database to the middle- (and eventually the client-) tier, while allowing that same schema to target multiple different database backends at the same time.
To the application code all that matters is the structure of data tables as defined in the schema, it does not need to be concerned about the layout of the physical database.
Why Column Mappings?
In an ideal scenario, the layouts of all databases supported by your application would be identical, and column mapping would not be necessary. In reality however, this is often not the case.
Reasons for targeting different database structures are manifold, including:
- Differences in SQL dialects that enforce different naming schemes on different database backends
- Targeting two or more existing databases that have been designed independently
- Designing a new database for the application, while still needing to access an old legacy database during migration
In these cases you will typically have databases that contain similar data, but use slightly different table structures or field names to represent the same type of data. One database might have a Customers table with CustomerID, Name, etc., while the other database has a table CUSTS, with CUSTOMER_NO and CUSTOMER_NAME fields.
Mapping Differences in Table Layouts
The Data Abstract approach to abstracting such different database layouts is to define your data tables to represent the data in the way that you want your application to see it. This representation can (and usually will) be based on one of the existing database layouts, but could also be designed independently.
For each backend database, you will then create individual SQL statements that select the appropriate data, and define a column mapping that connects the fields from your database to the fields defined in the schema.
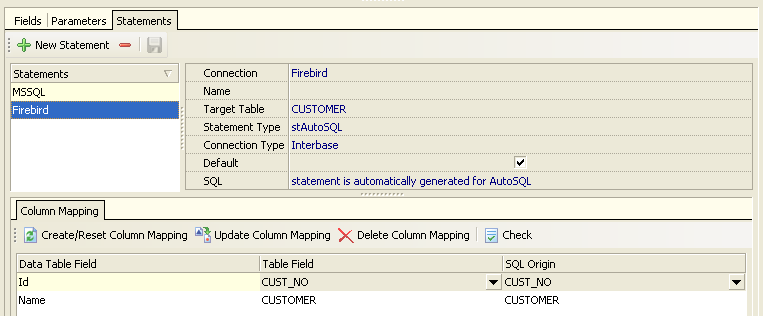
For example, CUSTOMER_NO would map to CustomerID, and CUSTOMER_NAME to Name:
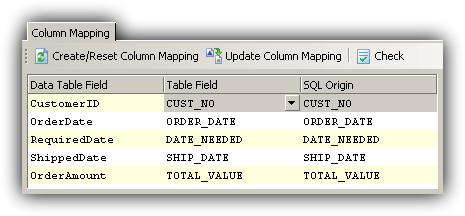
In this column mapping, Data Table Field is the field as defined in your schema - as mentioned before, this can match the field name in one of your database layouts, but can also be a fresh name (for example if all your database layouts used "awkward" or all-upper-case names, but you want proper PascalCase names in your schema).
Table Field is the name of the field in your physical database table, while SQL Origin is the name of the field returned from your query (which will be identical to the Table Field in most cases, unless your SQL query uses the AS directive to change field names).
Example
Let's see how Column Mapping can be used for targeting a data table on different database back-ends. In this simple example, the schema defines one data table (ListOfCustomers) with two fields: Id and Name.
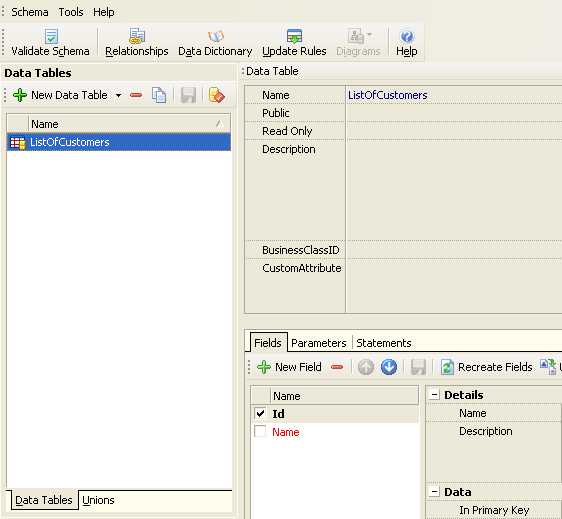
This data table can be filled with data from two different database back-ends, Microsoft SQL Server or Firebird. A connection was created in the schema for both database back-ends:
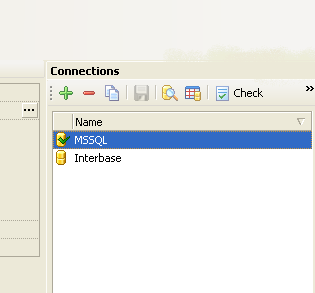
For the Microsoft SQL Server database, data is extracted from the Customers table within the Northwind database. For Firebird, data is extracted from the Employee database's Customer table. Column mapping was defined for each connection:
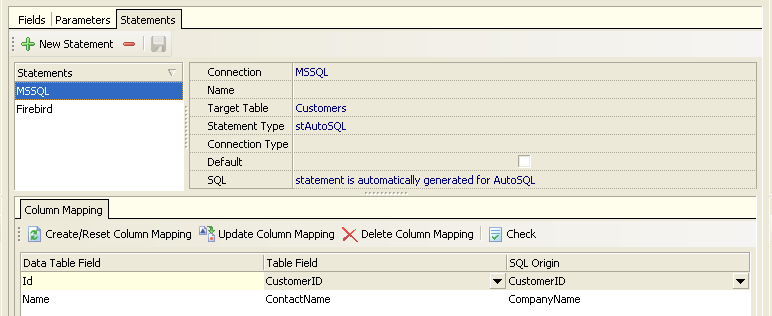
Data from the database backend can be extracted using an arbitrary SQL query or a stored procedure. This flexibility, together with column mapping, makes it easy to use existing data tables with any database source.